Anders EltonBigQuery and holidaysLearn how to create a table of vacation days in BigQuery using PythonNov 8, 2023Nov 8, 2023
Anders EltoninCompendiumUnderstanding BigQuery CostsIn this article you will learn what drives BigQuery costs and I will show a SaaS solution that can help you analyze the costs instantly!Mar 29, 2023Mar 29, 2023
Anders EltoninCompendiumGCP Workload identity federation on Gitlab passing authentication between jobsGitlab (late 2022) is relatively new to workload identity federation, and there are not many good templates or guides out there. The…Nov 30, 2022Nov 30, 2022
Anders EltoninCompendiumUsing dataform to improve data quality in BigQueryGet inspired on ways to use dataform to monitor and improve your data quality!Aug 31, 2021Aug 31, 2021
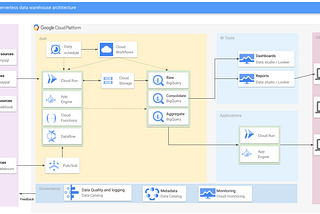
Anders EltoninCompendiumBuilding a serverless datawarehouse pipeline using GCPTraditionally, building a data warehouse requires massive capital investments in infrastructure, tools and licenses to get insight to your…May 7, 20211May 7, 20211
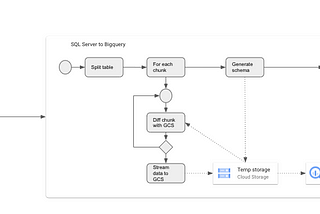
Anders EltonCopy SQL Server data to BigQuery without CDCSometimes you just want data from your source into your analytical tool and start doing experiments.Apr 23, 2021Apr 23, 2021
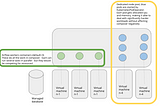
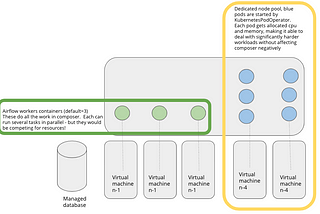
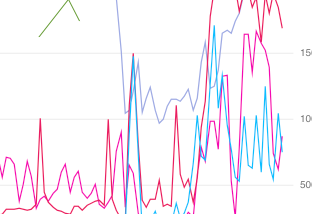
Anders EltoninCompendiumBest practises for KubernetesPodOperator in Cloud ComposerIn this post I will go through best practises on using the KubernetesPodOperator with examples. I will share dags and terraform scripts so…Oct 16, 20202Oct 16, 20202
Anders EltoninCompendiumArgo workflows as alternative to Cloud ComposerBackgroundMay 5, 20201May 5, 20201
Anders EltonTroubleshooting cloud composerIs cloud composer suddenly starting to miss deadlines? this blog might give hints to why composer is misbehaving and how to fix it!Apr 28, 20201Apr 28, 20201
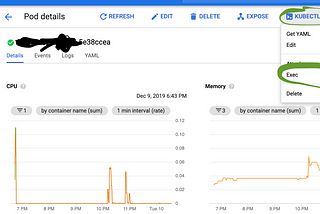
Anders EltoninCompendiumDebug a python workload that has gone silent (hung) inside kubernetesToday I was at a customer helping them to optimise their Cloud Composer setup. Cloud composer is a managed airflow installation, a job…Dec 9, 2019Dec 9, 2019